My notes on CRAQ - Chain Replication with Apportioned Queries
Introduction
I was reading this small summary of 3FS architecture in this blog - 3FS Performance Journal-1. In my opinion, it’s a pretty neat piece of work, and it mentioned that “Management Server” component kept track of all nodes addresses.
In this context, 3FS uses CRAQ, and the author has explained it in great detail later down the blog. So, why bother going through the paper CRAQ - Chain replication with Apportioned Queries? For fun, of course!
Broad strokes
The intent is to implement a Key-Value (or an Key-Object store as per the CRAQ paper) with the interface -
Interface
write(objectId, value)
value <-- read(objectId)
The system replicates data across multiple nodes and CRAQ is an improvement over classic chain replication, a method for replicating data across multiple nodes.
The nodes are chained as in a linked list, with a Head node and a Tail.
In classic chain replication, these are the node responsibilities:
- The head shall handle all the writes.
- The tail shall handle all the reads.
Each node maintains multiple version of a key. A key when newly written is dirty in the node. This new value is then sent to the downstream node to be written. (Imagine a doubly linked list). When the write reaches the tail the following happens:
- The tail stores the updated key value as clean.
- The tail sends the acknowledgement back to the upstream node.
- The tail cleans up older versions of the key.
- The same happens for the upstream node.
It’s understandable that the throughput of this setup is limited by the slowest node in the chain.
An example of this propagation of write is shown below:
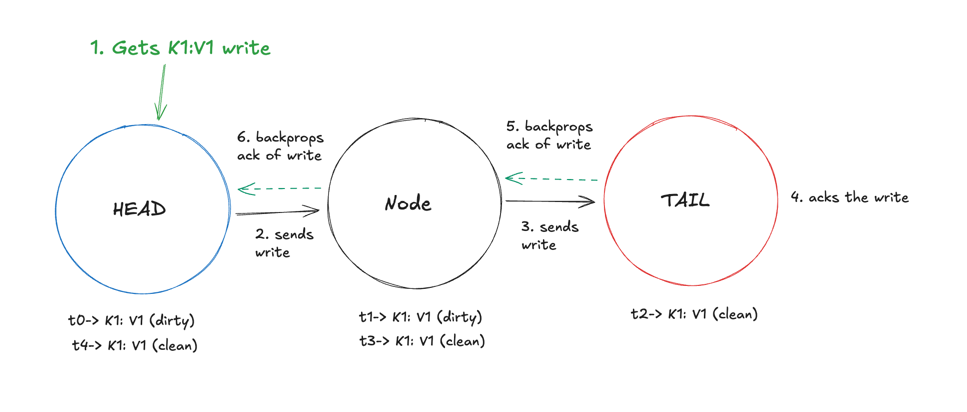
- The head receives a write request for K1 (value V1). It’s stored as dirty in the head.
- It’s then sent to the next node (Node 1) and stored as dirty there.
- The node 1 sends the write to the tail and the tail stores it as clean, while initiating a back-propagation of the write to the previous node (Node 1).
- The tail sends an ack to Node 1, and Node 1 stores the value as clean.
- Node 1 sends an ack to the head, and the head stores the value as clean. Note - In actual implementations, once the ack is received, the nodes clean up the dirty versions of the key (ex: t1 and t0 versions in Node 1 and Head).
With this in mind, it should be plausible to notice how this state might come across
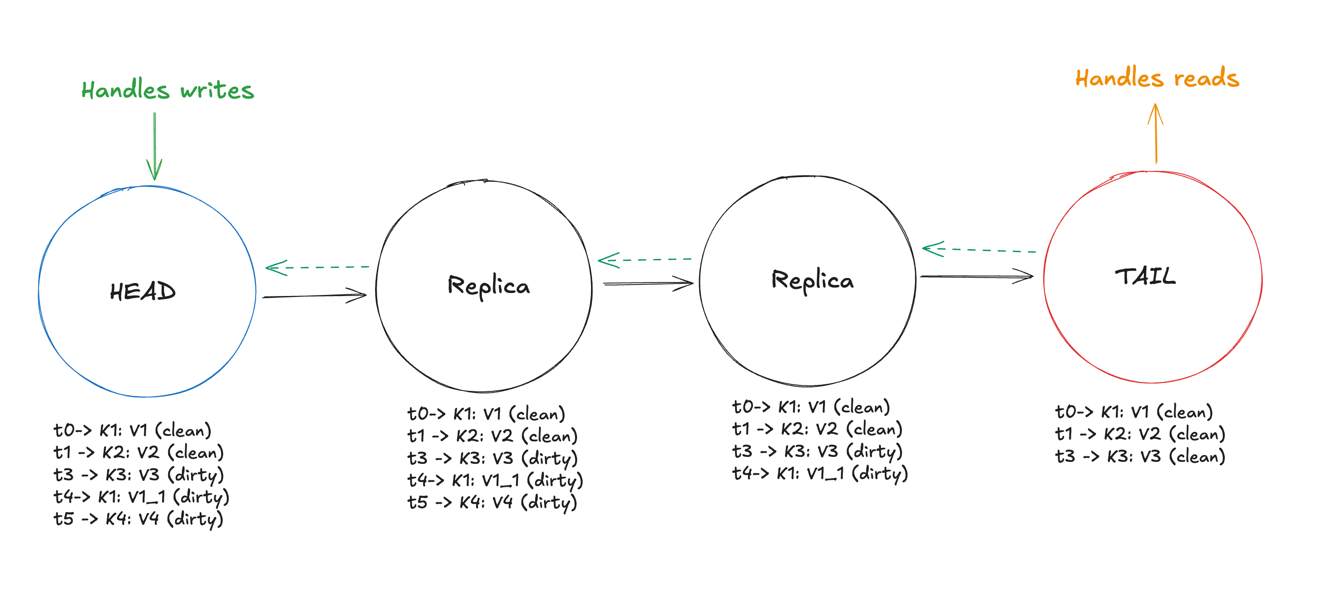 To reach this, the writes for K1, K2 have to be completely acked through the chain at t0 and t1. The K3:V3 version might be stuck at 3rd Node and have yet to send the write to the tail, hence the dirty state.
The updated value K1:V1_1 has also not reached tail yet, as for the k4:V4, it’s not yet being written to the third node.
To reach this, the writes for K1, K2 have to be completely acked through the chain at t0 and t1. The K3:V3 version might be stuck at 3rd Node and have yet to send the write to the tail, hence the dirty state.
The updated value K1:V1_1 has also not reached tail yet, as for the k4:V4, it’s not yet being written to the third node.
Enter, CRAQ
CRAQ is an improvement in the read-throughput context. With CRAQ, the clients can now be routed to read from other nodes in the chain, not only the tail. Naturally, this raises the concern for consistency. Whether the read from the intermediate node is consistent with the current state of acknowledged writes or not.
Let’s take a situation where the client is trying to read “K1” from the intermediate node.
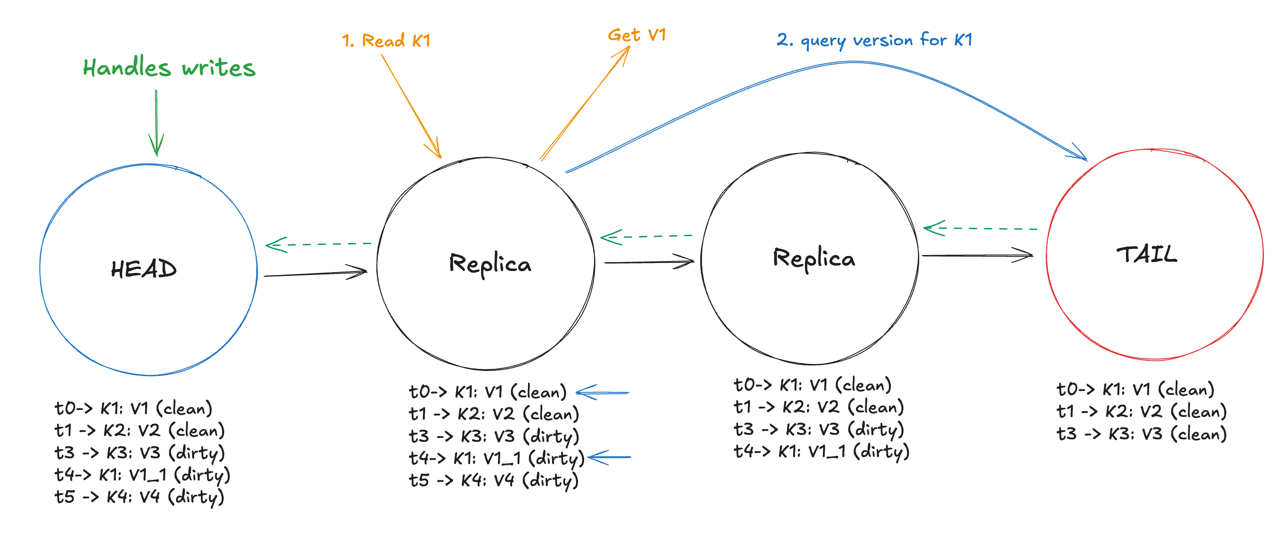
- The node first sees how many versions of the key are present in the node, if it were only 1 version present and the node cleans up all the dirty versions upon receiving an ack, it’s implicitly clean, and it could be returned right away.
- In our scenario however, there’s a dirty version present, so the choice is between the key at t0 and t4.
- The replica then attempts to check the latest version of the key “K1” from the tail.
- The tail returns the latest version of the key.
- The replica can now mark the latest version as clean and delete the old versions, i.e. the version query might act as an implicit acknowledgement as well.
- The replica can now return the value to the client.
This flavor is the Strong Consistency model. Referring to the paper, there are a couple more flavors of consistency that CRAQ supports:
- Eventual Consistency: It’ll allow the node to return the latest value known to it for a key. However, it means that if the client decides to read the same key from a different node, it might get an older version.
- PS: If the clients attempt to read from the same node, it’ll have monotonic read consistency, i.e. the client will always get the same or the latest version of key, not an older version.
- Eventual Consistency with Maximum Bounded Inconsistency: A node could serve uncommitted values but only till a certain version.
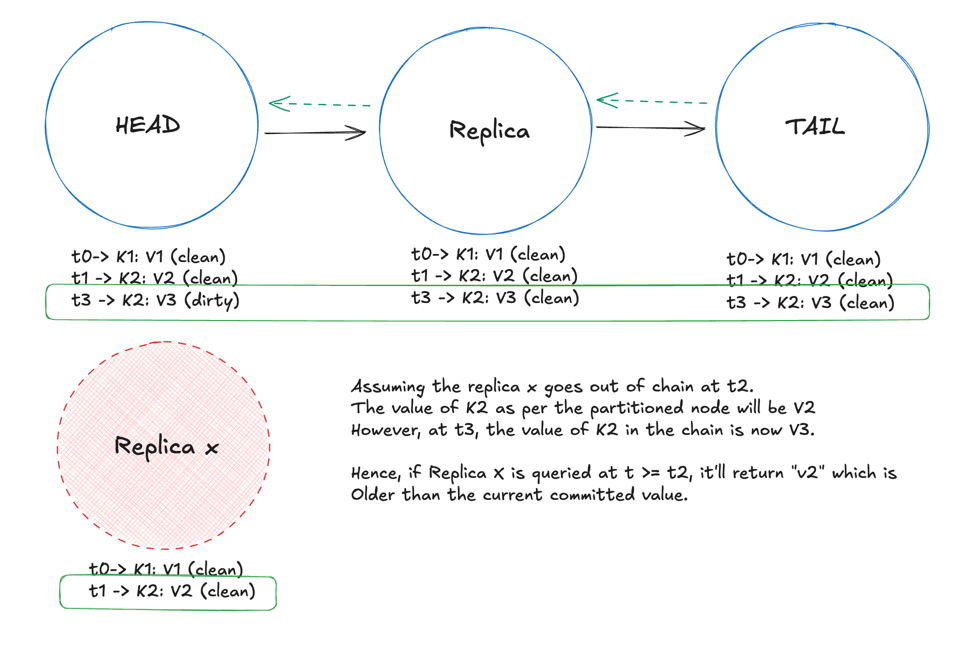
- This setup might lead to an interesting situation, let’s say if the entire chain is active and reachable. In this scenario, the dirty value being served might be newer than the committed value.
- However, if the chain is partitioned, then the value being returned might be older than the committed value. This is because the chain might have now maintained an updated value, but this particular node being out of the chain, will maintain an older version of the key. (illustrated below)
Is CRAQ self-sufficient?
To better re-phrase the question, could we just keep the nodes in a chain and let them manage the roles of each node in the chain and the chain sequence themselves? I will refer to this small excerpt from MIT’s 6.824 course (Lecture 9)
To answer this question, let’s understand what other nodes does an individual node needs to be in contact with. Imagine a doubly linked list for a better visualization.
- Next node (unless this node is the Tail)
- Previous node (unless this node is the Head)
- Tail node (in the event it’s the strong consistency setup).
Let’s try breaking it shall we?
What happens when the connection between Head and Node 1 is broken?
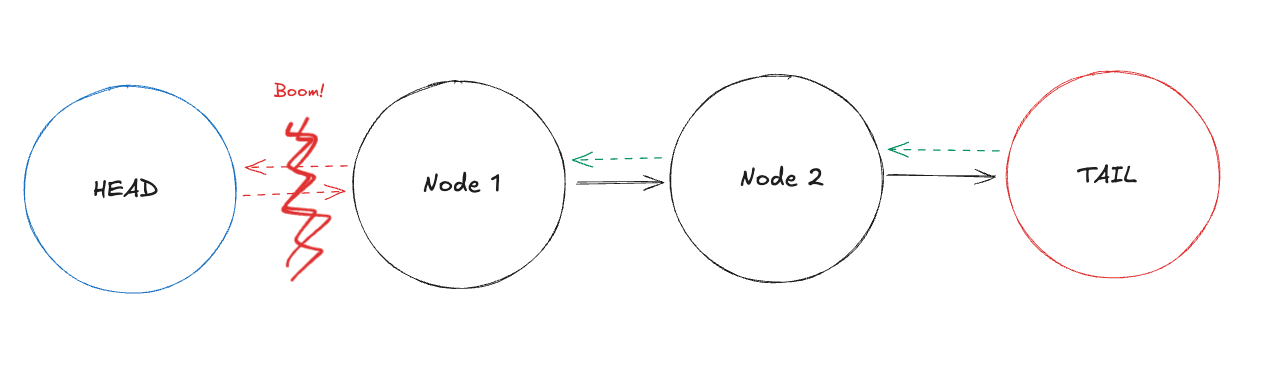
There could be a couple of scenarios brewing up here:
- The head keeps attempting to send the writes to Node 1, but it never receives an ack.
- The head might think that Node 1 is down and start sending the writes to Node 2 instead. (how would it know where’s Node 2? PS: Ironically, in solutions later, each node stores the entire chain topology anyway and not just the neighbouring nodes in the chain)
- Node 1 might think that the head is down and promote itself to be the new head.
- This is a split-brain scenario, and the node 1 might be accepting writes while the head is still trying to send writes to it.
So it’s not really self-sufficient, is it? It requires an external entity, or being specific, a configuration management entity to maintain the topology and roles of the nodes in the chain. The paper suggests Zookeeper to handle the topology. The video suggests Raft or Paxos can do the trick as well. What they’ll do is that they will maintain the topology of the nodes and their roles. Each node should subscribe to these management entities to get the latest topology and accordingly send the writes / send the acks to the right nodes.
So, even if the writes / back props are failing in the event of partitions, the node will be expected to keep retrying until the zookeeper sends a change in topology notification, hence avoiding split-brain scenarios.
If we need to use Raft anyway, why use CRAQ at all?
- CRAQ is a read-optimized solution, and it does not require the leader to be involved in the reads.
- In the event of a write operation
- In RAFT: The leader has to send the writes to the other followers as well, assuming the leader has 5 followers, the leader has to send 5 messages per write.
- In CRAQ/CR: The head sends the write to the next node only, this reduces the number of messages sent to 1 per write.
Failure Handling
Now that we have established that we might use an external entity to handle the node roles, it’s a tad easier to imagine how does failure recovery work here. In the paper, they have kind of explained it in Node Addition sections. In a general idea, the failure recovery works as follows:
- If the head is failed, its next node can take up as the new head.
- If the tail is failed, the previous node to the tail will be the new tail.
CRAQ shines in the event when something might go wrong during the failure recovery. If you remember, the Nodes back-propagate the committed claen values of a key to it’s predecessor. In CRAQ, rather than just sending the clean value, a node also sends the outstanding dirty values to the previous node. This way, if a new node is added to the chain, it can respond to future acknowledgements as well! Pretty neat.
Conclusion
CRAQ is fun, I skipped the paper’s elaboration regarding the performance evaluation and features like mini-transactions, appending to the key type transactions are well elaborated within the paper, there’s nothing more I could add to it.
Acknowledgements
Big thanks to Govind and Debadree for taking out time to review the draft of this post!