Demystifying Druid - Streaming ingestion internals - Supervisors
Long time no see :) I believe this will be first post in almost 3 months.
Quick personal update - I am now a Senior Software Engineer in RnD team at Imply Data, primarily working on improving OSS Druid. This blog post will be serving like my own lecture in a somewhat legible format (my obsidian is a mess) while I am trying to make sense of the code base.
Introduction
Alright, quick recap, Druid is a real-time analytics database, designed for fast aggregations and low-latency queries on large datasets. You can go through the architecture in the official docs.
In this post, I care about Streaming ingestion internals of druid. I shall be diving deep into what an ingestion task looks like from the perspective of the
Overlord and how it manages the ingestion tasks that read from streams like Kafka, Kinesis, etc.
Now here are a few concepts that I will be using a lot in this post, so a quick recap (or glossary if you will):
Glossary
| Term | Description |
|---|---|
| Segment | A unit of data in Druid, which is a time-ordered collection of rows. Segments are immutable and are created during ingestion. They are stored on Historical nodes and can be queried by Druid’s query engine. |
| Tasks | It’s a job that runs on druid’s servers (Indexers, Middle Managers, K8s pods) for ingesting/compacting/moving segments (and in some cases, helping with queries as well). |
| Overlord | AKA Indexing Service, It’s a service that’s responsible for accepting tasks, coordinating task distribution among various runners, providing status and logs for these tasks while and maintaining appropriate locks for the tasks. For more, you can read here. |
| Supervisors | It handles a streaming ingestion-task and takes care of orchestrating segment handoffs and managing multiple ingestion tasks to read from the stream partitions. |
| segment handoffs | Transferring the ownership of a newly created segment from realtime ingestion nodes (Middle Managers / Indexers) to Historical nodes. |
Magic of Supervisors
Why do I need a supervisor?
Imagine, you have a kafka topic with 100s of partitions. To read these partitions, you now need 100s of tasks and someway to orchestrate and verify whether these tasks are doing what they are supposed to do. It sits like a nice abstraction layer that does this heavy lifting for you.
Specs
With that out of the way, let’s take a look at supervisor specs. There are multiple specs for a Supervisor (depending on which kind of stream this supervisor is ingesting from), for the context of this post, I will be focusing on the KafkaSupervisorSpec that is used to ingest data from Kafka topics. (You can find the general specs here)
A quick look at the ioConfig of a supervisor gives us a good intuition of what it is doing
taskCount: Et voilà, this is the number of ingestion task groups (will explain later) that will be created by the supervisor that will actively read records from the streams. So, if there arempartitions in the Kafka topic, the supervisor will map the partitions among thetaskCountnumber of task-groups (in the simplest round-robin fashion).autoScalerConfig: This is used for dynamic scaling of the ingestion tasks based on the partition lags. So, the supervisor must be having some way to monitor the lag and tune around the number of tasks.replicas: EachtaskGroupwill havereplicasnumber of tasks that will be reading from the same partition. This is useful for fault tolerance and to some extent, helping with the queries.taskDuration: Hmm another hint! It indicates that each task that’s spawned by supervisor will run for a certain duration. So, the supervisor will also be responsible for spawning new tasks after the earlier ones are finished.period: How frequently the supervisor performs its task management duties.
Supervisor architecture
One can imagine a supervisor as a event loop that periodically polls for Notices from a blocking Linked Queue. Kindly refer to the diagram present in #10524- Dynamic autoscale Kafka-Stream ingest tasks for a good idea of how the supervisor would look like.
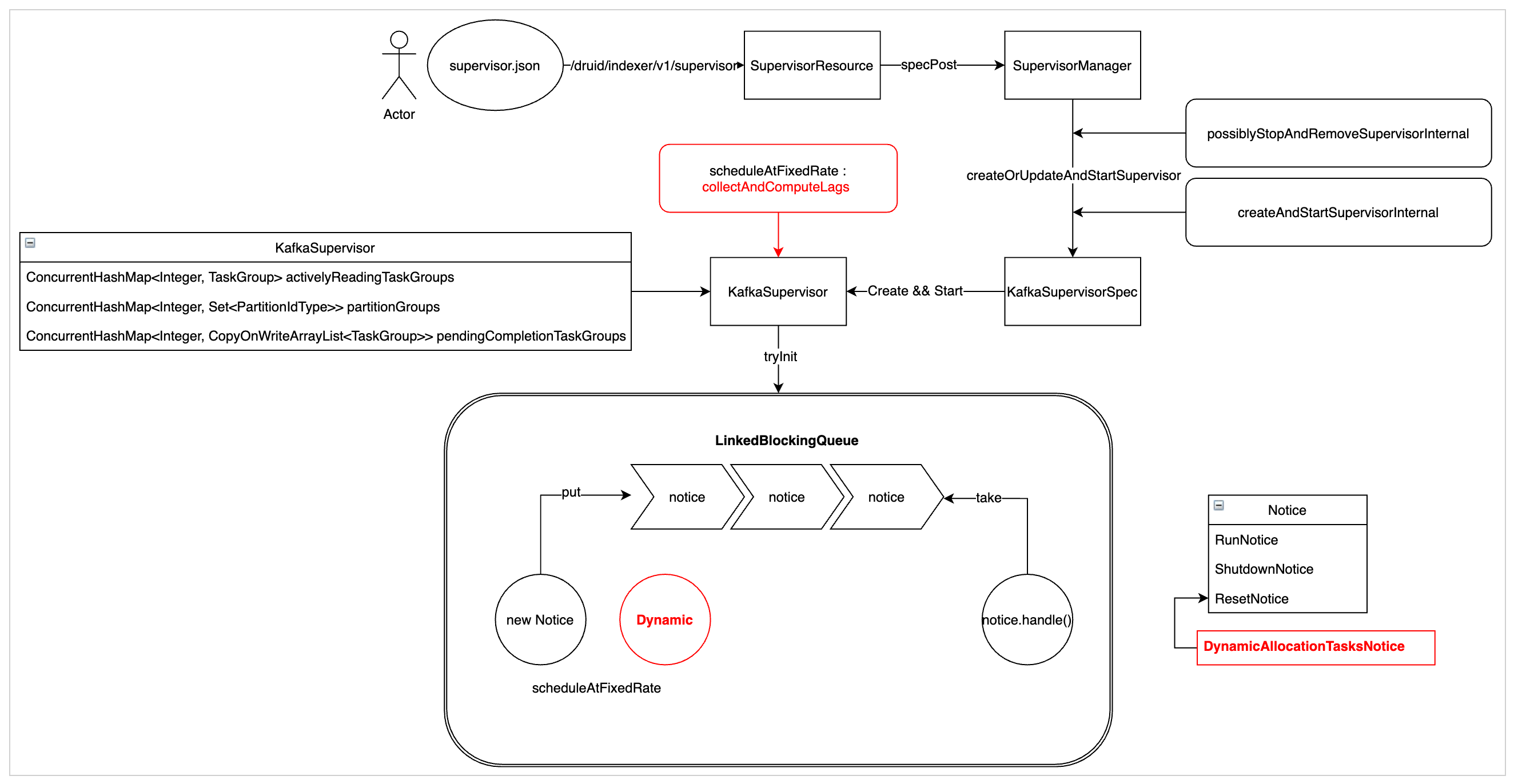
The Notices mentioned below are of 4 kind:
RunNotice: This is the notice that triggers the supervisor to run its management loop (elaborated later in the post).ShutdownNotice: This one tells the supervisor to attempt a graceful shutdown and stop all the actively running tasks.ResetNotice: This one deletes all the relevant state from the overlord’s metadata storage (basically, resetting the offsets to an earlier stage) and clearing in-memory queues.DynamicAllocationTasksNotice: This is sent by auto scalers to the supervisors to tell that what should be the current number of actively reading task groups (ifautoScalerConfigwas set in the spec).
Now that we have established the general architecture of a supervisor, I want to spend the rest of the time we have on the RunNotice bit. That’s where the meaty parts lie for the management of a supervisor.
RunNotice management loop
Before diving deep into the RunNotice management loop, we’ll quickly talk about some in-memory data structures that each supervisor maintains. You can check out the code at SeekableStreamSupervisor.java
TaskGroup: It’s the main data structure that holds the information regarding which partitions are being read by which set of tasks. If 5 partitions are assigned to ataskGroupwithreplicaof 1, then there will be 5 separate tasks, each reading from a single partition. At a time, there are no more thantaskCounttask groups being managed by a supervisor.activelyReadingTaskGroups: A map betweentaskGroupIdandTaskGroupobject. The tasks present in theseTaskGroupsare the ones that are actively reading records from the stream.pendingCompletionTaskGroups: A similar map but for the task groups that have been asked to shut down by the manager and publish their segments.partitionGroups: A mapping between theTaskGroupand the assignedpartitionIDs. Note: No partition can be assigned to more than oneTaskGroupat a time.taskMaster: Imagine this as an interface via which supervisor submits its tasks to ataskQueuein the Overlord, that will internally take care of fanning the task out to the real-time ingestion nodes (Middle Managers / Indexers).taskClient: An interface that allows the supervisor to communicate with the tasks it has spawned. It can be used to send notices to the tasks, check their status, etc.
Ofcourse there’s more elements like spec, ioConfig, tuningConfig etc. however with the knowledge we have so far, we should be able to understand the flow I have mentioned below.

Sweet, so in a RunNotice.handle():
- It goes to our metadata storage (could be
MySql,DerbyorPostgres) and fetches the last committed offsets for each partition and maintains a set of partition IDs. It then asks an interface with the streams (we call itrecordSupplier) to fetch the lags and the current known partitions.- If suddenly we realise that the number of partitions have changed, supervisor says uh-oh! please shut down all the active task groups, save the progress, we gotta start again with new partition mappings.
- At this point, if the partition is not part of any taskGroup, the
partitionGroupsare also updated to reflect the new partition mappings. This is important because it ensures that no partition is left unassigned and all partitions are being read by some task group.
- It asks the
taskMasterto fetch all the tasks that are currently present in thetaskQueue. A quick check is done to see if the tasks are valid and if we already have them (either inactivelyReadingTaskGroupsorpendingCompletionTaskGroups). If not, where should it be placed (or if it simply should be killed.) - Each tasks status is updated and their start time is captured in-memory (if not done already, may happen in case of newly discovered tasks).
- Now, we check how long an actively reading
taskGrouphas been running for (each task group has a fixed duration, after which it’s asked to shut down.)- You can configure that hey, don’t shut down more than
ioConfig.stopTaskCountat a time. - If there is early handoff configured / new partition sets are seen / auto scaler kicks in, all the tasks in the taskGroups are asked to shutdown anyway.
- Btw, when shutting down, we also perform a checkpoint of the current offsets for partitions handled by each
taskGroup.
- You can configure that hey, don’t shut down more than
- The supervisor then checks the status of all the publishing task groups, if any task within the task group fails, it’s a no-go. It discards the progress of this taskGroup and resets the offsets for the said partition and it’s read again.
- It checks the statuses of the actively reading task groups, If any task (out of all the
replicasconfigured) is inSUCCESScase, supervisor considers it to be good and asks it to start publishing the segments. - All good so far? Supervisor has one last thing to do, create new tasks for the task groups that have been just added to
activelyReadingTaskGroups. It ensures at leastreplicastasks are being run for each task group.
Conclusion
Astute readers must have noticed that the supervisor, as the name suggests, is just a management layer. It does not actually read from the streams, it just manages the tasks that do. For now, I will leave the details of the ingestion tasks for the next post (That’s a beast in its own right). Till then, I hope you try out druid yourself and see how it works.
Thanks!