Demystifying Druid - Streaming ingestion internals - Tasks & Runners
Welcome back to the second part of the series on Druid ingestion internals. In my previous post Demystifying Druid - Streaming ingestion internals - Supervisors we went through the internals of a
Supervisor. As discussed previously,
the supervisor is just an orchestrator that manages the ingestion tasks that eventually read from the streams. In this one, I want to dive deeper into what these tasks look like and what makes them ingest rows after rows of data.
Introduction
In druid, you could imagine a
Task as a job that runs on druid’s servers (could be Indexers, Peons or K8S pods working as peons, at least for the ingestion perspective). For seekable streaming ingestion, this task is SeekableStreamIndexTask.
However, a task alone won’t cut it, it needs an implementation of ChatHandler for the outside world (in this case, Supervisor) to interact with it.
For our SeekableStreamIndexTask, this implementation is called SeekableStreamIndexTaskRunner.
For the rest of this post, I will be diving deep into the constructs of a
SeekableStreamIndexTaskRunner to make sense of the ingestion process.
Glossary
| Term | Description |
|---|---|
| TaskToolbox | Small utility class that helps in task’s functions. A toolbox may have different dependencies injected to it depending on which env did the task runner spawn in. |
Uncovering the SeekableStreamIndex TaskRunner
Each SeekableStreamIndexTaskRunner is instantiated with a TaskToolbox and a
SeekableStreamIndexTask object. The toolbox internally contains tons of utility classes, however I’d like you to focus on the following ones for now:
StreamChunkParser: A parser that reads from the stream applies required transformations if needed and converts the rows toInputRowobjects that the runner can understand.- Metrics managers:
RowIngestionMeters: A metric manager of sorts that keeps the track of rows ingested, and the ones that failed to be ingested with different reasons (like thrown away, unparsability etc).SegmentGenerationMetrics: This class tracks the metrics related to segment generation like number of segments created, rows pushed, segments handed off etc.
RecordSupplier: A supplier that reads from the stream and supplies records to the parser. -Appenderator: Arguably the most important class in the ingestion process. The prime responsibility of this class is to index data (in-memory and on-disk) and possibly serve queries on top of it. We’ll talk more about this later.StreamAppenderatorDriver: An abstraction on top ofAppenderatorthat helps in additionally performing tasks that aloneAppenderatorcan’t do (notably segment handoffs to Historicals, and publishing segments to deep storage etc).
These classes should be enough to get us started, I’ll explain the appenderator in more detail as we reach the relevant sections. Talking about the sections, I’d like to break down the further post in sections with the overall flow looking like this:
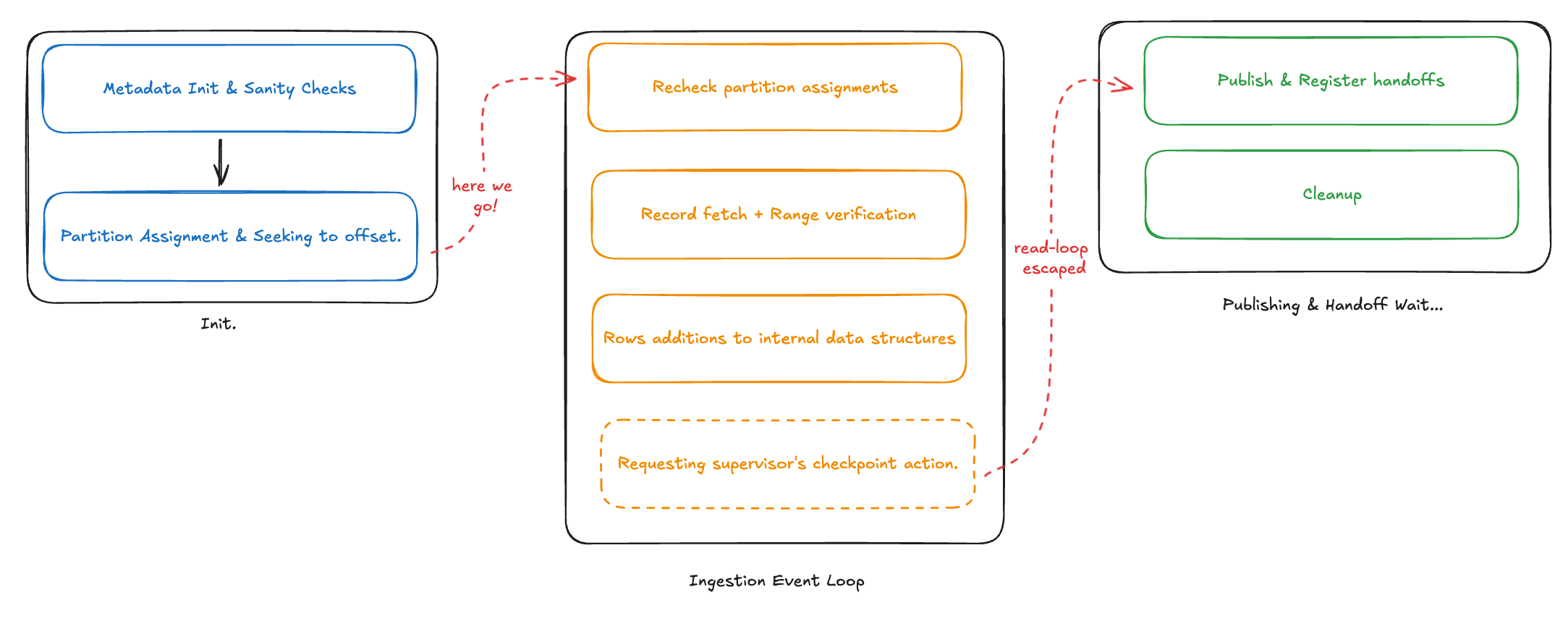
1. Initialization
Technically, you could include the creation of all the classes I mentioned above in this section, however I’ll skip it for the juicy bits. During initialization, the runner has only these bits to take care of:
- The driver’s
startJob()is triggered that looks for any existing metadata in the base directory pertaining to this task. This may include loading existing segments and sinks in the memory, initiliazing relevant executors etc. - If any segments are found in the metadata, they are loaded in the
segmentslist of the runner. - If it’s a fresh task, none of the above happens. Only the starting offsets are loaded from record suppliers and set as
currentOffsets. - Existing segment persists / publishes are resumed (if any).
- Partitions are assigned to the task and the starting offsets of
recordSupplierare seeked for each partition. - The ingestion state of the loop is set to
BUILDING_SEGMENTS, while the status of runner is set toRUNNING.
2. Ingestion Loop
- A re-check of partition assignments is done (just in case there are changes like paritions closed off, scaled out etc).
- If there’s a shutdown requested, last sequence being read is checkpointed or the sequences to read have been set to 0 (no partition to read) runner sets the status to
PUBLISHING, i.e., no fresh records shall be read and the task is in finishing stages. - Any background persists / publish failures are reported (yup, we keep publishing segments incrementally).
- If this sequence is not going to be read anymore (no more new records), this sequence is marked for publish as well.
- The actual record reading starts now:
- Records are fetched from the
recordSupplier(which reads from the stream) in batches. - It’s decided whether the fetched records should be parsed or not (by checking sequences numbers to avoid duplicates).
- Once added to
Appendator, it’s checked if persist is needed or not (based on max rows per segment, max segment size etc). - If either the last condition, or the max time between last checkpoint has been crossed, a segment publish is triggered.
- Records are fetched from the
- Once all the above is done, the runner self triggers a pause and sends a
CheckPointDataSourceMetadataActionto the supervisor to be able to checkpoint the offsets read so far.
3. Persisting & Publishing segments
- Once there are no more records to read, or a stop has been requested by the supervisor / admin, the runner sets its status to
PUBLISHING. - The runner asks the driver to publish all the segments that are not published yet, as a callback to the publish future, a handoff is registered.
- All the publishing futures are awaited on before we shut down the publishes.
Before ending the post, I’d like to add a few internal notes regarding the beauty of Appenderator and StreamAppenderatorDriver,
the appenderator is the data structure where ingested rows are indexed in-memory and served for queries. Let’s take a deeper look at that.
Some Appenderator internals
Before diving too deep into addition, we need to talk about Sinks and FireHydrants. You could imagine a sink as a series of hydrants that belong to a segment, however, a hydrant is the data structure that actually holds the index and hence, is the primary unit where the row addition / query happens. So, in a way, you could say that a sink would eventually churn out a “big final segment” while the hydrants maintains temporary segments within themselves that are queryable.
The following diagram might help visualize this better:
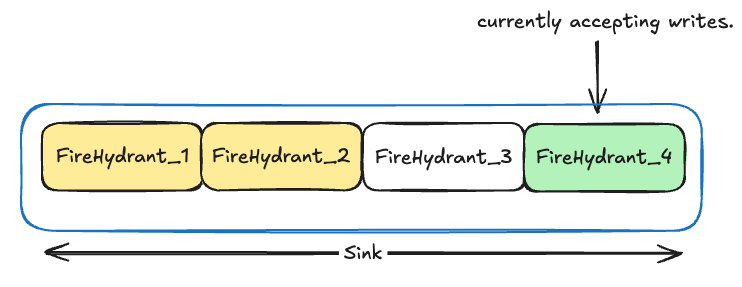
- The Yellow boxes are the hydrants that have been persisted to disk.
- The White one (FireHydrant_3) is a fire hydrant currently in-memory but not writable.
- The Green one (FireHydrant_4) is the current writable hydrant.
Whenever a row is added to the appenderator, append() is called, internally it breaks down the row addition to the following steps:
- Fetching the appropriate segment interval for this row.
- An appropriate sink is created / fetched for this segment interval.
- From the sink, the current hydrant is fetched and within the hydrant’s index, the row is added. A pre requisite of this would be that the hydrant must be writable.
- Amazingly enough, once a row is added into the index, we check whether we need to persist the current hydrant or not (row number check, memory checks etc). If needed, the current hydrant is flushed to disk and a new hydrant is swapped in.
Conclusion
Phew, still around? This was indeed a long one. I hope you enjoyed me peeling the layers of this ingestion process, my next attempt would be to cover how the task helps in serving these queries but I guess that can wait for the next edition :).
Thanks!